从 Claude Code 的实战中聊聊:Skills 到底该怎么写?
原文来自 Anthropic 工程师 Thariq 的分享,本文在其基础上做了重新梳理与补充。

如果你用过 Claude Code,大概率已经接触过 Skills 这个东西。简单说,Skills 是 Claude Code 里最常用的扩展机制之一——灵活、易上手、方便共享。但也正因为太灵活了,很多人其实不太清楚到底该做哪种 Skill、怎么写才算好、什么时候该分享给团队。
Anthropic 内部目前有数百个 Skill 在实际使用中。Thariq 这篇文章把他们踩过的坑和沉淀下来的经验做了一次系统整理。这里我重新梳理成中文技术文档,方便大家快速上手。
Skill 是什么?不只是 Markdown 文件
很多人一开始会觉得 Skill 就是一个 .md 文件,但这其实是个常见的误解。
Skill 本质上是一个文件夹。除了主体的 Markdown 之外,里面还可以放脚本、资产文件、数据、配置等各种东西。Agent 会自动发现这些内容,在合适的时机去读取和操作。在 Claude Code 里,Skill 还支持一系列配置项,比如注册动态 Hook 等等。最有意思的 Skill,往往就是巧妙利用了这些配置选项和文件夹结构的。
如果还没接触过 Skill,可以先看 官方文档 或者 Anthropic 最近发布的 Agent Skills 课程。
九种常见的 Skill 类型
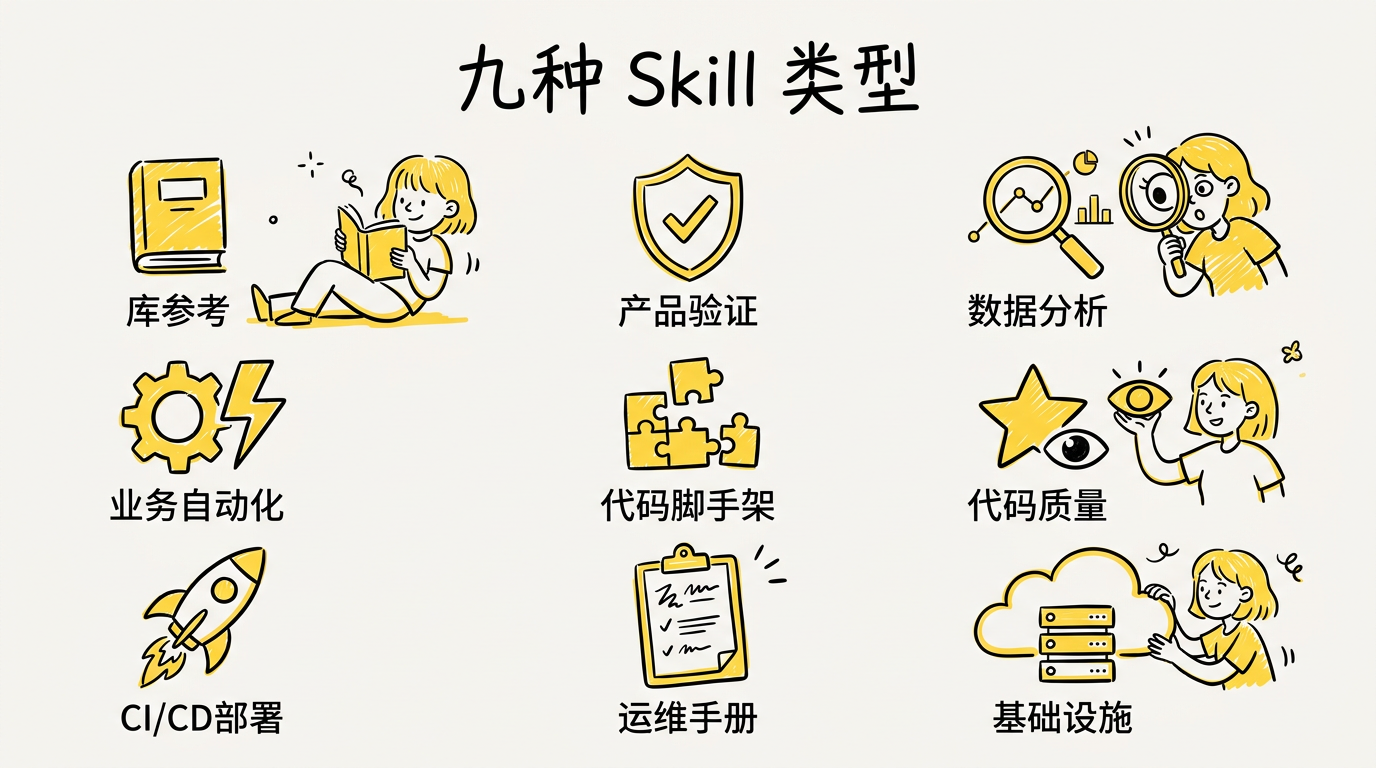
Anthropic 内部梳理了所有 Skill,发现它们基本上可以归到以下九个类别。好的 Skill 通常只属于其中一类;如果同时跨了好几类,反而说明设计上可能有问题。
1. 库 & API 参考(Library & API Reference)
解释如何正确使用某个库、CLI 工具或 SDK。可以是内部库,也可以是 Claude 容易搞错的第三方库。这类 Skill 通常会带上一组参考代码片段和常见坑点列表。
举几个例子:
billing-lib:内部计费库的边界情况和易错点internal-platform-cli:内部 CLI 的每个子命令,附带使用场景示例frontend-design:让 Claude 更好地理解你的设计系统
2. 产品验证(Product Verification)
描述如何测试或验证代码是否正常工作。通常会配合 Playwright、tmux 这类外部工具来做实际验证。
这类 Skill 的价值非常大,值得让一个工程师花一整周时间来打磨。一些进阶技巧包括:让 Claude 录制它测试过程的视频,或者在每个步骤强制加入状态断言。
例子:
signup-flow-driver:跑完 注册 → 邮件验证 → 引导流程,用无头浏览器在每一步做状态断言checkout-verifier:用 Stripe 测试卡跑结账 UI,验证发票确实落到了正确状态tmux-cli-driver:给需要 TTY 的交互式 CLI 做测试
3. 数据获取与分析(Data Fetching & Analysis)
连接数据源和监控系统的 Skill。可能包含带凭据的数据获取库、特定的 dashboard ID,以及常见的数据分析工作流。
例子:
funnel-query:明确”注册 → 激活 → 付费”各环节要 join 哪些事件表,以及 canonical user_id 到底在哪张表里cohort-compare:对比两个用户群的留存或转化,标出有统计显著性的差异grafana:数据源 UID、集群名称,以及”问题 → dashboard”的对应查找表
4. 业务流程与团队自动化(Business Process & Team Automation)
把重复性的工作流自动化成一条命令。这类 Skill 通常指令本身很简单,但可能依赖其他 Skill 或 MCP。一个好习惯是把之前的执行结果存成日志,方便模型保持一致性并回顾历史。
例子:
standup-post:聚合 ticket tracker、GitHub 活动和之前的 Slack 消息,生成格式化的 standup,只展示增量create-<ticket-system>-ticket:强制走 schema 校验(合法枚举值、必填字段),创建后自动 ping reviewer、在 Slack 贴链接weekly-recap:合并 PR + 关闭的 ticket + 部署 → 生成格式化的周报
5. 代码脚手架与模板(Code Scaffolding & Templates)
为代码库里的特定功能生成框架模板。当脚手架中有自然语言描述的需求(纯代码覆盖不了的部分)时,这类 Skill 尤其有用。
例子:
new-<framework>-workflow:用你的注解体系搭建新的 service/workflow/handlernew-migration:migration 文件模板 + 常见坑点create-app:预置好认证、日志、部署配置的内部新应用模板
6. 代码质量与审查(Code Quality & Review)
在组织内部推行代码质量规范,辅助代码审查。可以包含确定性的脚本或工具来提高可靠性,也适合作为 Hook 或 GitHub Action 自动运行。
例子:
adversarial-review:派一个”新鲜视角”的子 Agent 来挑刺,修完再迭代,直到只剩鸡蛋里挑骨头的级别code-style:强制执行代码风格,特别是 Claude 默认做不好的那些testing-practices:指导如何写测试、测什么
7. CI/CD 与部署(CI/CD & Deployment)
帮助拉代码、推代码、做部署。这类 Skill 可能会引用其他 Skill 来收集信息。
例子:
babysit-pr:盯一个 PR → 重试 flaky 的 CI → 解冲突 → 开启 auto-mergedeploy-<service>:构建 → 冒烟测试 → 灰度流量切换并对比错误率 → 回归则自动回滚cherry-pick-prod:隔离 worktree → cherry-pick → 解冲突 → 用模板发 PR
8. 运维手册(Runbooks)
接收一个问题信号(Slack 讨论、告警、错误签名),走一套多工具排查流程,产出结构化报告。
例子:
<service>-debugging:把”症状 → 工具 → 查询模式”做好映射,覆盖高流量服务oncall-runner:拉告警 → 检查常见嫌疑 → 格式化输出排查结果log-correlator:给一个 request ID,把所有可能经过的系统的日志都拉出来
9. 基础设施运维(Infrastructure Operations)
执行日常维护和运维操作,其中一些涉及需要加防护栏的破坏性操作。
例子:
<resource>-orphans:找出孤立的 pod/volume → 在 Slack 发通知 → 等一段时间 → 用户确认 → 级联清理dependency-management:组织内部的依赖审批流程cost-investigation:存储/出口带宽账单飙升的排查,包含具体的 bucket 和查询模式
写好 Skill 的实战技巧
知道该做什么 Skill 之后,怎么才能写好它?以下是 Anthropic 团队积累的经验。
别说废话
Claude 本身对你的代码库已经有不少了解,对编程也有自己的默认判断。如果你做的是知识型 Skill,应该把重点放在”打破 Claude 惯性思维”的信息上。
frontend design skill 是个好例子——它是 Anthropic 的一位工程师反复和用户迭代出来的,核心目标就是让 Claude 摆脱那些经典的”AI 审美”,比如 Inter 字体加紫色渐变。
好好维护”坑点清单”
任何 Skill 里信息密度最高的部分,就是 Gotchas(坑点)章节。这些内容应该来自 Claude 在实际使用中反复犯的错误。理想情况下,你会随着使用不断往里面追加新发现的坑。
善用文件系统和渐进式信息披露
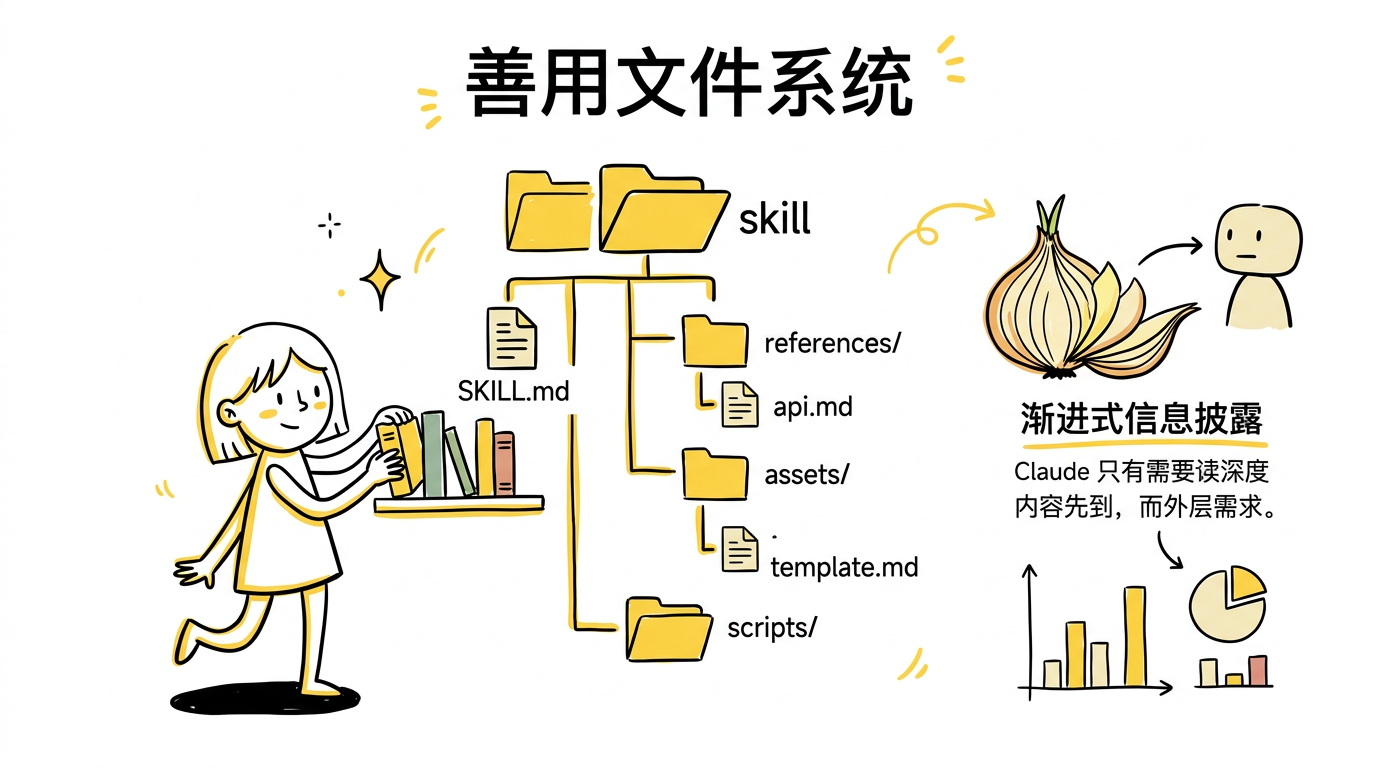
再强调一遍:Skill 是一个文件夹,不是一个文件。你应该把整个文件系统当作上下文工程和渐进式信息披露的工具。
具体来说:
- 告诉 Claude 你的 Skill 里有哪些文件,它会在合适的时候自动去读
- 最简单的做法是用额外的 Markdown 文件来组织详细内容,比如把函数签名和用法示例拆到
references/api.md - 如果最终输出是 Markdown,可以在
assets/里放一个模板文件 - 参考文件夹、脚本、示例代码等,都能帮助 Claude 更高效地工作
别把 Claude 框死
Claude 会尽量遵守你的指令。但因为 Skill 会被反复复用,如果指令太死板,反而会在很多场景下适得其反。给 Claude 足够的信息,但也要留给它适应具体情况的灵活度。
比如不要写”在第三步必须用 grep 搜索”,而是写”在需要定位代码时,优先使用搜索工具”。
做好初始化设置
有些 Skill 启动时需要用户提供上下文。比如一个发 standup 到 Slack 的 Skill,可能需要知道发到哪个频道。
一个好的模式是在 Skill 目录里放一个 config.json。如果配置没初始化,Agent 就会主动询问用户。如果想让 Agent 展示结构化的多选题,可以指示 Claude 使用 AskUserQuestion 工具。
description 字段是写给模型看的
Claude Code 启动时会扫描所有可用 Skill 的 description 列表,然后据此决定”这个请求有没有对应的 Skill”。所以 description 不是给人看的摘要,而是告诉模型”什么时候该触发这个 Skill”的判断依据。
写 description 的时候要想的是:用户说了什么话、出现了什么关键词,Claude 应该想到调用这个 Skill。
给 Skill 加上”记忆”
有些 Skill 可以通过在自身目录下存储数据来实现记忆能力。简单的可以是一个追加写入的文本日志或 JSON 文件,复杂的可以是一个 SQLite 数据库。
比如 standup-post 可以维护一个 standups.log,记录每次发过的内容。下次运行时 Claude 读自己的历史,就能知道昨天之后发生了什么变化。
注意:Skill 目录下的数据在升级时可能被清除。应该把数据存到稳定路径下,目前可以用 ${CLAUDE_PLUGIN_DATA} 这个变量来获取每个插件专属的稳定数据目录。
内置脚本,让 Claude 做组合而非重建
给 Claude 提供脚本和函数库,让它把精力花在组合和决策上,而不是每次都从零开始写模板代码。
比如在数据分析 Skill 里,你可以提供一组从事件源拉数据的辅助函数。Claude 就可以在运行时动态生成脚本来组合这些函数,回答像”周二发生了什么?”这样的问题。
按需 Hook
Skill 可以包含仅在被调用时才激活的 Hook,且只在当前会话有效。这对那些很有用但不该一直开着的功能特别合适。
比如:
/careful:拦截rm -rf、DROP TABLE、force-push、kubectl delete等危险操作。只在碰生产环境时开启,一直开着会烦死人/freeze:阻止对特定目录之外的文件进行任何编辑。调试时很有用——“我想加日志但别让 Claude 顺手’修’了不相关的代码”
分发与团队协作
Skill 的另一大价值在于团队共享。主要有两种方式:
方式一:提交到仓库。把 Skill 放在 ./.claude/skills 目录下。对小团队来说简单直接,但每个 Skill 都会增加一点模型的上下文开销。
方式二:内部插件市场。通过 Claude Code Plugin Marketplace 让团队成员自行安装需要的 Skill。适合团队规模扩大后使用。
市场管理
Anthropic 内部没有一个专门团队来审核 Skill。他们的做法是让好的 Skill 自然浮现:先放到 GitHub 的沙箱目录里,在 Slack 里推广试用。等有了足够的使用量(由 Skill 作者自己判断),再提 PR 正式加入市场。
一个提醒:低质量或重复的 Skill 很容易泛滥,所以在正式发布前做好把关很重要。
Skill 之间的组合
你可能会需要 Skill 之间互相依赖。比如一个”CSV 生成”Skill 调用”文件上传”Skill。目前 Skill 系统还没有原生的依赖管理机制,但你可以直接在 Skill 里按名称引用其他 Skill,模型会在它们已安装的情况下自动调用。
如何衡量 Skill 的效果
Anthropic 通过一个 PreToolUse Hook 来记录 Skill 的使用情况(示例代码)。这样可以找出哪些 Skill 很受欢迎,哪些触发率低于预期。
写在最后
Skill 是一个强大而灵活的 Agent 扩展工具,但目前还处于早期阶段,大家都在摸索最佳实践。与其把这篇文章当作一份标准指南,不如把它看作是一袋实用的经验。
Anthropic 内部大多数 Skill 都是从几行文字加一条坑点开始的,随着 Claude 踩到更多边界情况,才逐渐变得丰富和可靠。最好的学习方式,就是动手去做、反复迭代、看看什么对你有用。